8.1 配列とデータフレームの操作
8.1.1 NumPy

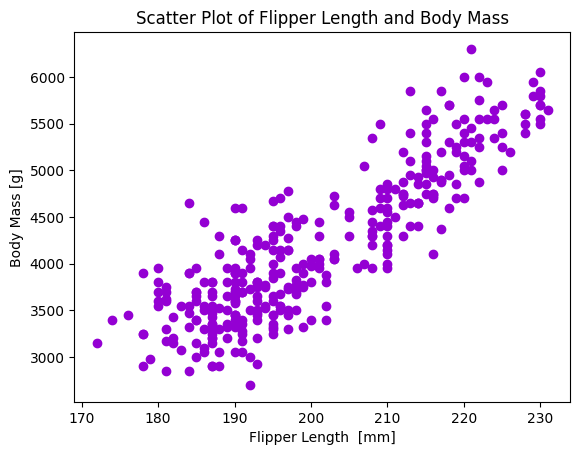
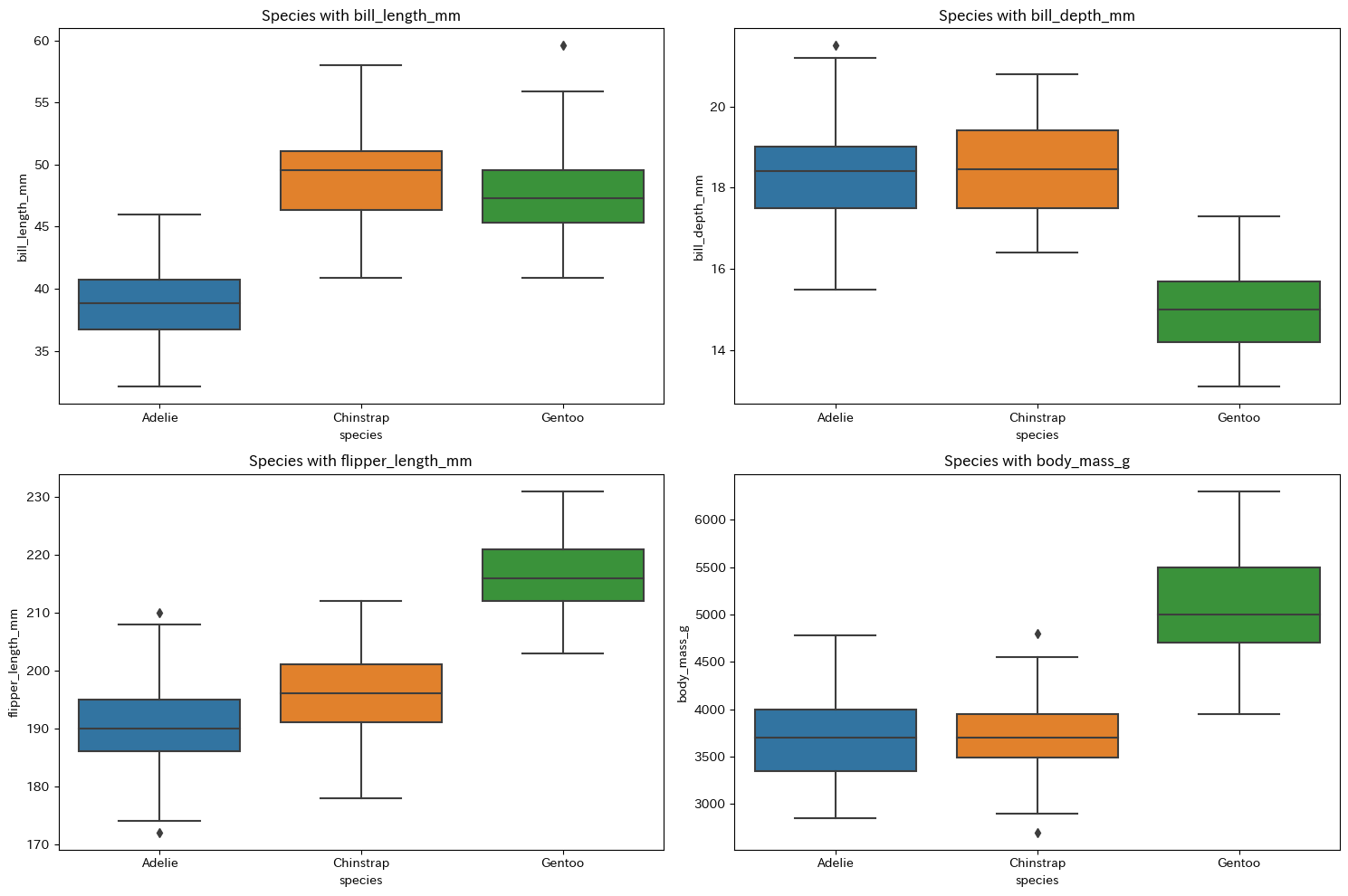
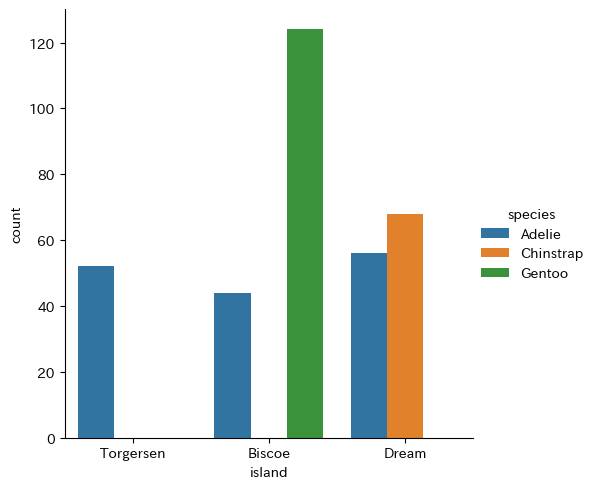
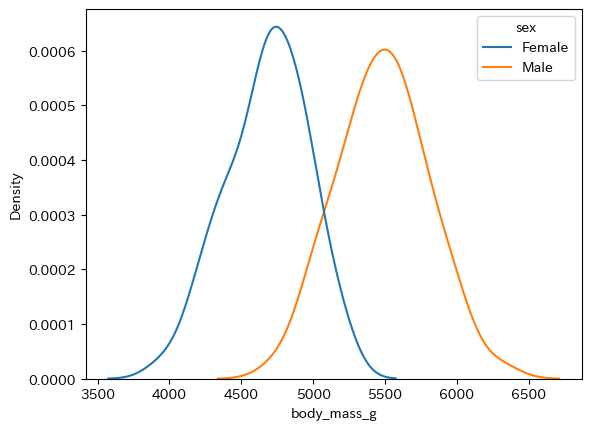
本ウェブページは『超入門 はじめてのAI・データサイエンス』第8章に記載されたコードを埋め込んでいます。第4章で使い方を学んだColab上で,Pythonによる探索的データ分析 を行います。
最初は NumPy ライブラリを用いた配列に関するコードです。下記 コード1 では,NumPy ライブラリを読み込み,二次元の ndarray を作成 します。
コード 1
import numpy as np
a = np.array([[1, 2, 3],[4, 5, 6]])
aコード2 は,a という行列オブジェクトの形状を返します。
コード 2
a.shape下記 コード3 は,すべての要素に 1 が入った,引数により指定する形状の行列を作ります。NumPy の ones についてもっと知りたい人は こちら を参照して下さい。
コード 3
b = np.ones((2, 3))
b下記 コード4 では,累算代入演算子 を用いて,行列 b を定数倍したものを b に上書きしています。
コード 4
b *= 10
b下記 コード5 は,b のデータの型を返します。
コード 5
b.dtype下記 コード6 は,行列 b の型を変換するコードの例です。
コード 6
b = b.astype(int)
b下記 コード7 は,行列加算のコード例です。
コード 7
a + b下記 コード8 は,配列の形状変換の例です。
コード 8
c = a.reshape(3, 2)
cコード9 は,行列 c の各要素に 6 を足すコードです。
コード 9
c = c + 6
c下記 コード10 は,行列の積を返すコードです。
コード 10
d = np.dot(a, c)
d下記 コード11 は,行列の要素積を返すコードです。
コード 11
e = a * b
e下記 コード12 では,配列 e の平均を返します。
コード 12
e.mean()下記 コード13 は,配列 e の axis=0,縦方向の平均を返します。
コード 13
e.mean(axis = 0)下記 コード14 は,配列 e の axis=1,横方向の平均を返すコードです。
コード 14
e.mean(axis = 1)8.1.2 Pandas
ライブラリ pandas は,通常 下記 コード15 のようにエイリアス pd を付けて読み込みます。第6章でも用いましたし,データ分析には欠かせないライブラリです。これからも事あるごとに使っていきます。
コード 15
import pandas as pd